| 逐次実行 | if文 | for文 | while 文 |
|---|---|---|---|
| <文> <文...> |
if <式>: <文...> else: <文...> |
for var in iterable :<文...> else: <文...> |
while <式>: <文...> else: <文...> |
 |
 |
 |
 |
今日の講座では、while文による繰り返しで、フィボナッチ関数を再定義してみます。
python3の制御構造:while文
if文,while文, for文: 制御文/制御構造break/continue/pass/...(Ellipsis)代入式
実行時間の測定:timeitモジュール
などについてご説明します。
fib()関数の別定義¶これまで使ってきた漸化式を元にしたフィボナッチ数列の関数は次のような物でした。
def fibr(n:int)->int:
"""
returns the n-th fibonacci number.
"""
if n in (0,1):
return 1
return fibr(n-1) + fibr(n-2)
この再帰的に定義されたfibr(n)は大きなnに対して、効率が悪く、実行速度も遅いという問題があります。
そこで、再帰を繰り返しに展開したフィボナッチ関数を次に示します。
Pythonの繰り返しにはfor文もありましたが、ここではwhile文を使って書いてみました。
Notes:
この実装は Python.org に掲載されている$n$を超えない最大のフィボナッチ数を求める関数を少し変形して、$n$番目のフィボナッチ数を求める関数に書き換えたものです。
新しいフィボナッチ数列の定義は次のようになりました。
この定義ではPython3の代入式と while文 が使われています。これらの文法について次に解説します。
def fibw(n:int)->int:
"""
returns the n-th fibonacci number.
"""
if n in (0, 1):
return 1
a=b=1
while (n := n-1 ) > 0:
a, b = a+b, a # a: f_{k}, b:f_{k-1}
return a
二つのフィボナッチ数列を求める関数(fibw, fibr)の値を比較してみましょう。
print("\n".join([f"{n=:} {fibw(n)=:} {fibr(n)=:}" for n in range(6)]))
n=0 fibw(n)=1 fibr(n)=1 n=1 fibw(n)=1 fibr(n)=1 n=2 fibw(n)=2 fibr(n)=2 n=3 fibw(n)=3 fibr(n)=3 n=4 fibw(n)=5 fibr(n)=5 n=5 fibw(n)=8 fibr(n)=8
このように二つの関数の値は一致します。
この関数では、一時変数 a,b に フィボナッチ数列のある時点iでの値($f_i$)と一つ前の値($f_{i-1}$)を保存します。
その時次のステップi+1での フィボナッチ数列の値($f_{i+1}$)は、a+b, 一つ前のフィボナッチ数列の値($f_{i}$)は aです。
| i | 1 | 2 | 3 | 4 | ... | n-1 | n |
|---|---|---|---|---|---|---|---|
| f_{i} | 1 | 2 | 3 | 5 | ... | a | a+b |
| f_{i-1} | 1 | 1 | 2 | 3 | ... | b | a |
例えば、i=3の時、aは3、bは2となっています。
a, b = a+b, a
を実行すると、aは5、bは3となって、 i=4のフィボナッチ数列の値と、一つ前のフィボナッチ数列になります。
これを n-1回繰り返すと、fib(n)が求まるというわけです。
Note:
ここでもし、ループの中が次のようなプログラムだったとします。
a=a+b b=a
i=3でaが3、bは2の時にこのプログラムを実行すると, プログラムの実行後はaは5となりますが、bも5になってしまいます。ループの中身を
b=a a=a+bとすると、今度は、実行後の値は
bは3,aは 6 (= 3+3)になってしまいます。これを避けるためには、ループ中のプログラムを
t=a a=a+b b=tとすることもできますが、pythonでは、
a,b = a+b,bと簡単に書くことができます。
[fibr(n) for n in range(10)]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
Note:
for文を使ったバージョンはこちら。
def fibl(n:int)->int:
"""
returns the n-th fibonacci number.
"""
if n in (0, 1):
return 1
a=b=1
for i in range(1,n):
a, b = b, a+b
return b
[fibl(n) for n in range(6)]
[1, 1, 2, 3, 5, 8]
まず、関数定義の中の、while文から見ていきましょう。
while文は、if文、for文と同じく、Pythonでのプログラムの流れを制御するための文です。
if文は条件分岐を作ります。while文とfor文は繰り返し(ループ)を作ります。C言語などではこのほかにも,repeat-until構文、do-while構文、switch-case構文などをもつ言語もありますが、pythonの制御構造はこの三つ(if, for,while)だけです。
(2021/10/27 追記:3.10ではmatch-case構文が導入されました。)
| 逐次実行 | if文 | for文 | while 文 |
|---|---|---|---|
| <文> <文...> |
if <式>: <文...> else: <文...> |
for var in iterable :<文...> else: <文...> |
while <式>: <文...> else: <文...> |
|
|
|
|
Notes: 構造化定理(こうぞうかていり、英: Structure theorem)とは、任意の一入力・一出力関数は、順次(sequence)、選択(ifthenelse)、繰り返し(whiledo)の3つの基本制御構造からなる関数と等価であることを主張する定理である[1]。構造化プログラム定理(structured program theorem) あるいは ベーム-ヤコピーニの定理(Böhm-Jacopini theorem)とも呼ばれる.(wikipediaより)
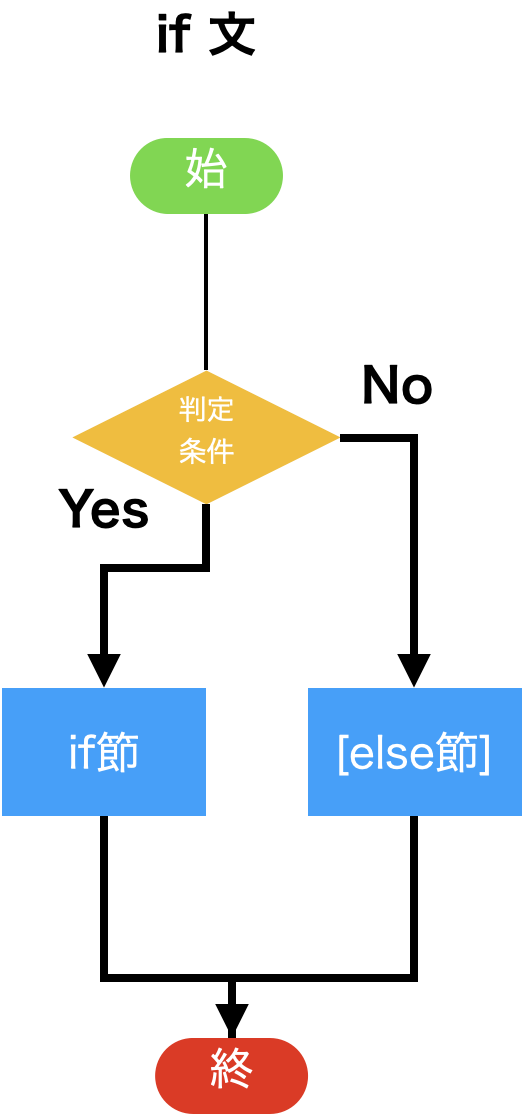
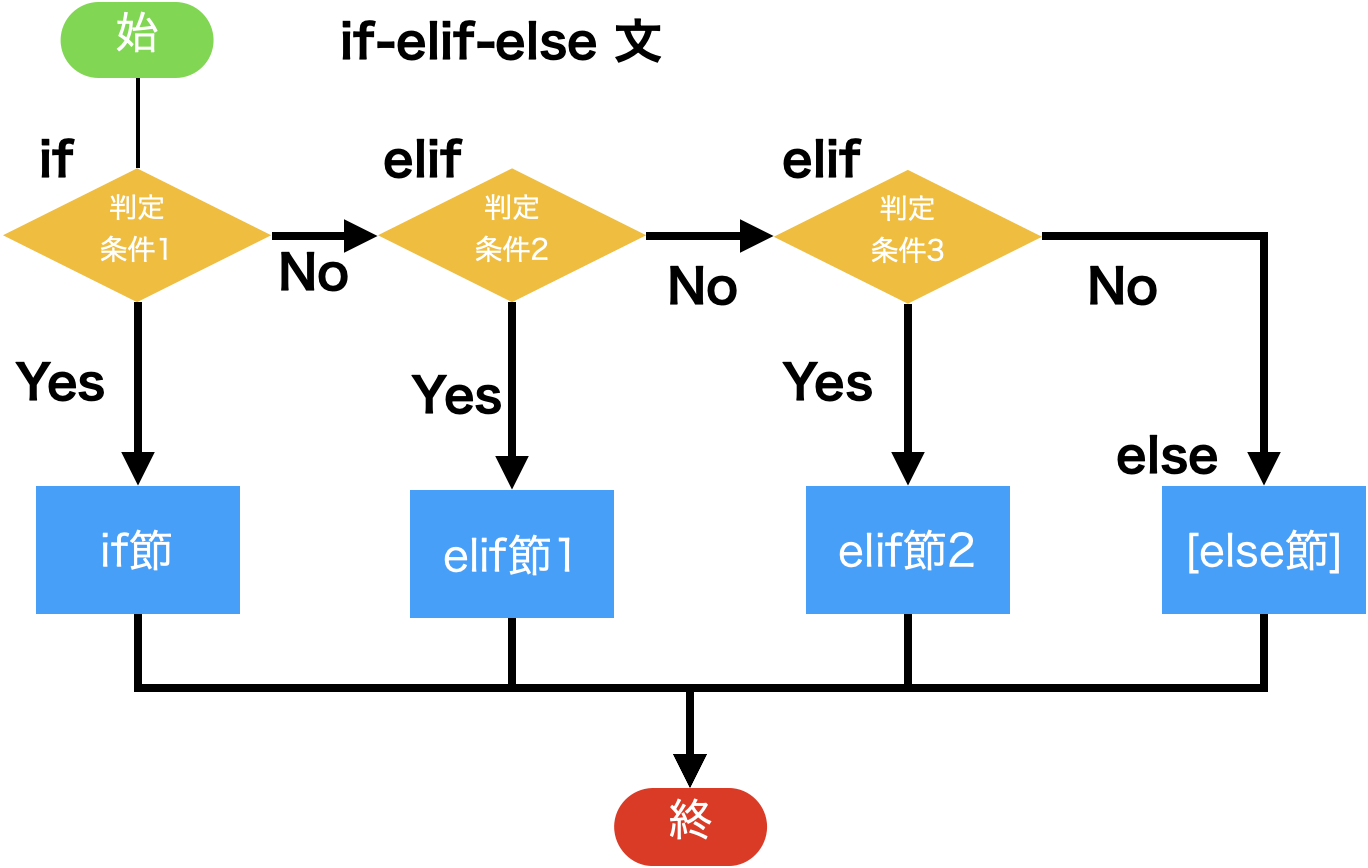
if文:¶if <式> :
<プログラムブロック-1>
elif <式-2> :
<プログラムブロック-2>
else:
<プログラムブロック->
elif節は必要なだけ繰り返してもよい。 (なくてもよい)elif はelse-ifの省略else節はなくてもよいが、一つのif文には二つ以上あってはいけない。<式>が論理値として真(True)になった時、対応する<プログラムブロックを実行する。
ifあるいはelse節に指定されたどの式も論理値としての値が偽(False)の場合、else節の<プログラムブロック>が実行される。
| if-elif-else文 |
|---|
| if <条件>: <文> ... elif <条件>: <文> ... else: <文> |
 |
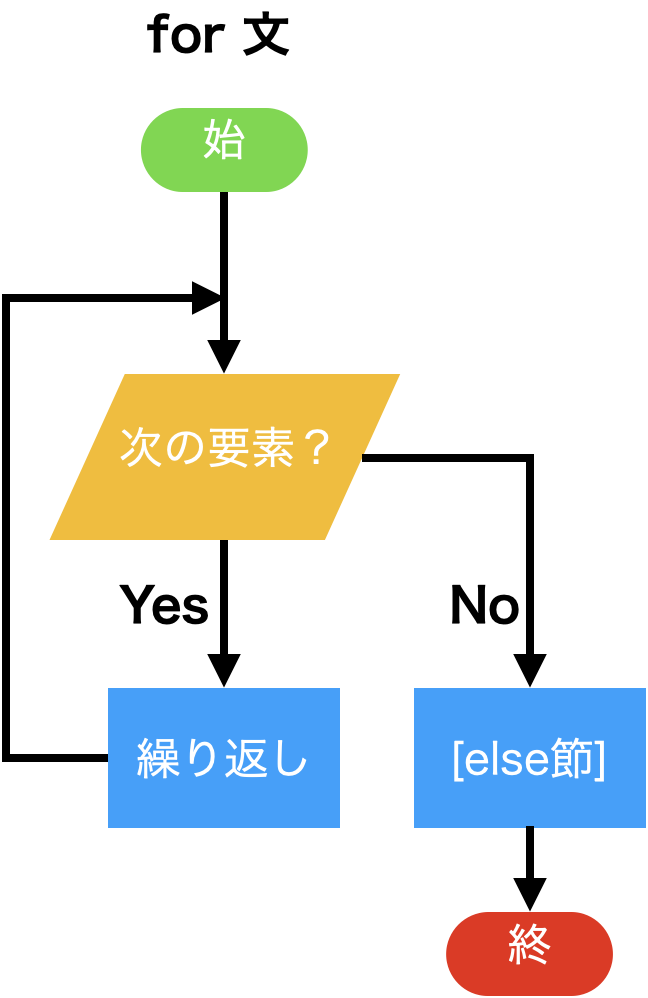
for文:¶for <識別子> in <> <繰り返し指定> :
<プログラムブロック>
for文は終了します。for <識別子> in <> <繰り返し指定> :
<プログラムブロック-1>
else:
<プログラムブロック-2>
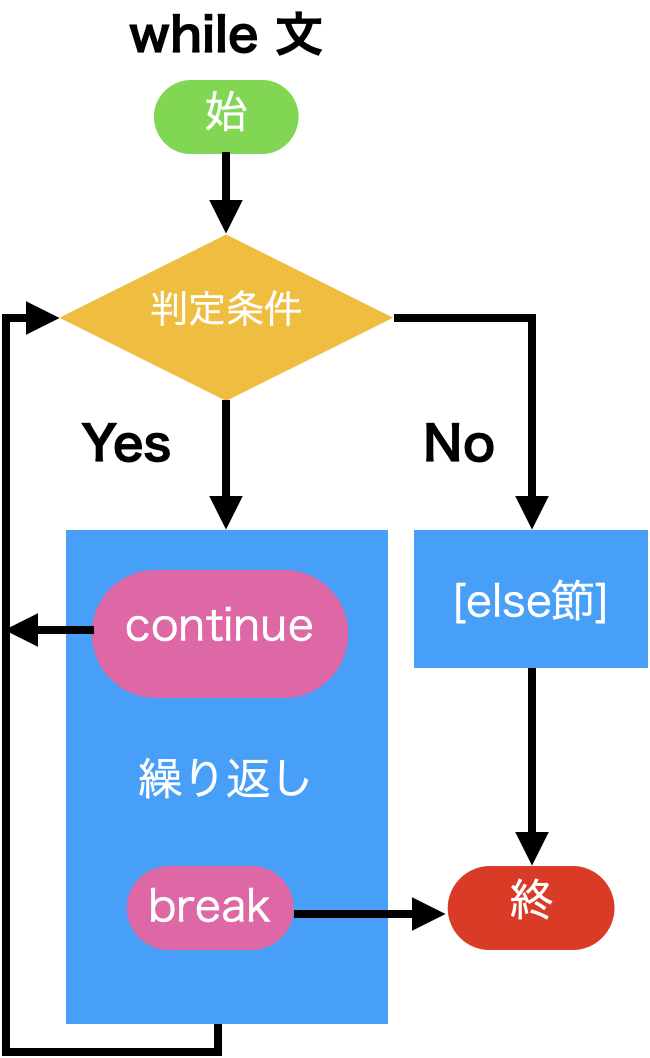
for文を終了します。while <式> :
<プログラムブロック>
<式>の値が真であれば、<プログラム ブロック> を実行して、ループを繰り返します。while <式> :
<プログラムブロック1>
else:
<プログラムブロック2>
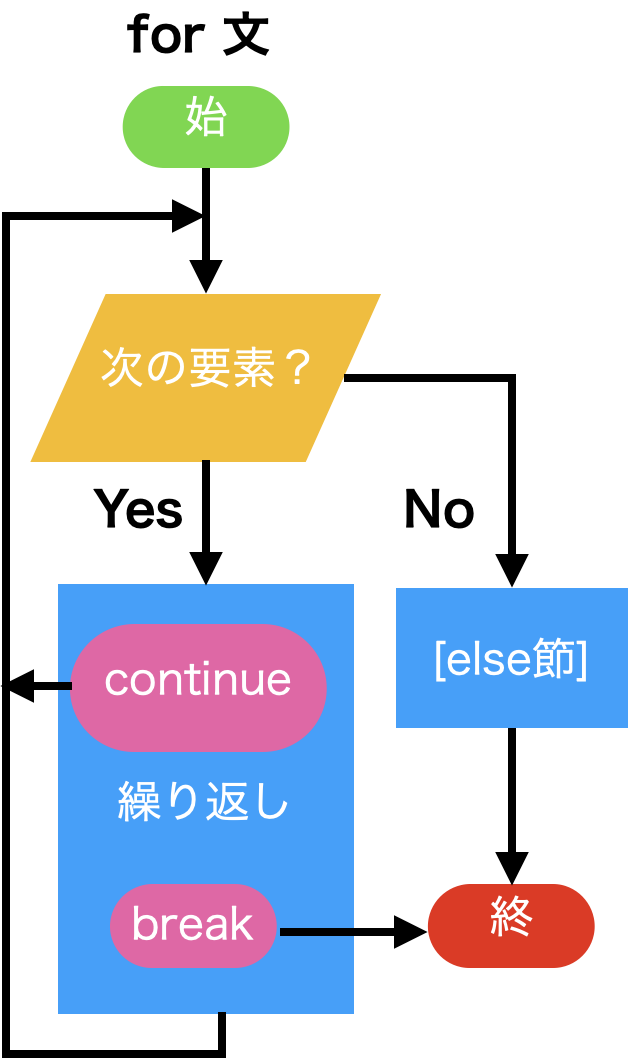
<式>の論理値としての値が真であれば、<プログラム ブロック1> を実行して、ループを繰り返す。<式>の論理値としての値が偽であれば、<プログラム ブロック2> を実行して、ループを終了する。break文/continue文/pass文/... (Ellipsis)¶whileやforで作られたループを処理の途中で中断し、次の要素に進んだり、ループを抜け出すこともできます。
continueおよびbreakはこれらの目的に用意されています。

Note: 書棚の本から目的とする本を内容を確認しながら、探すことを考えてみましょう。 書棚から順> 番に、
- 始: 書籍を手に取ります。
- タイトルをみて、目的の書籍でないことが明らかなら、次の本をチェックします。(
continue)- 内容をチェックして、目的の本であることがわかれば、ここで探索を終了します。(
break)
- 書棚にチェックしていない本がまだあっても、作業を終了します。
- 次の書籍がまだあれば、 始: に戻ります。
- 書棚の書籍がもうなければ(
else節)、この書棚には目的の本はないということです. さあどうしましょう?
break文/continue文/pass文/... (Ellipsis)¶whileやforで作られたループを処理の途中で中断し、次の要素に進んだり、ループを抜け出すこともできます。
continueおよびbreakはこれらの目的に用意されています。
break/continue¶while文、for文の(else節を除く) <プログラム ブロック>はbreak文あるいはcontinue文 を含むことがあります。
break文はbreak, continue文はcontinueだけ含む文です。continue文が実行されると、プログラムブロックの実行はそこで終了し、次の繰り返しに制御が移ります。break文が実行されると、プログラムブロックの実行はそこで終了し、while文あるいはfor文の次の文に制御が移ります。| for文 + coninue/break | while 文 + coninue/break | |
|---|---|---|
 |
|
 |
pass文/... (Ellipsis)¶プログラム開発中には、詳細は後々に埋めることとして、全体の枠組みだけを作っていくことがあります。pass文や...(Ellipsis)はそのような場合の埋め草として使われます。たとえば、
while condition :
do_something()
else:
pass
def do_something(arg):
...
といった具合です。pass文も... も 何もしない(No-op) を表現しています。
a = b = 1
a = 1
b = 1
a, b = 1, 1
などの文は代入文です。
代入文は変数に式を評価した値を割り当てます。 (Pythonでは代入文より割り当て文と呼んだほうがいいかもしれない。個人的見解です)
<識別子> = <式>
<識別子> = <識別子> =... = <式>
<識別子> , <識別子>, ... = <式>, <式>,... #式の左右で要素の数が一致していること
<識別子> , <識別子>, ... = <シークエンス> #識別子の数とシークエンスの要素数は一致していること
<識別子0> , <識別子1>,...,*<識別子n> = <シークエンス> #シークエンスの要素数 は`n`以上
Pythonの代入文はC言語のそれと異なり、値を持ちません。
(n := n-1)¶walrus(セイウチ) expression とも呼ばれます。
while文、if文などの条件節で、代入式(<識別子> := <式>)を使うことができます。
代入式では<識別子>への<式>の代入を行い、その式の値が代入式の値となります。
| walrus(セイウチ) |
|---|
 |
# 例
if (v:=fibw(10)) > 0:
print(v)
89
Note:
代入式 , walrus(セイウチ) expression はpython 3.8で導入されました。
C-言語では代入文はなく、元々代入式であったので、なにを今更という感じかもしれません。
if v:=fib(10) > 0: print(v)と書いてもエラーにはなりませんが
if v:=(fib(10) > 0): print(v)と解釈されてしまうので、注意が必要です。曖昧さをなくすため、
if (v:=fib(10)) > 0: print(v)とするのが良いでしょう。
Note:
C/C++言語での、代入式を使った次のプログラムと比較してみましょう。
#include <iostream> int main(void){ int r=0; (((r=1) || (r=r+2)) && (r=r+4)); std::cout << r << std::endl; r=0; (((r=1) && (r=r+2)) || (r=r+4)); std::cout << r << std::endl; }
if文、while文には 分岐/継続のための条件式が必要です。
条件式は比較演算子や論理演算子を組み合わせてつくることができます。
値の比較はC言語とほぼ同じです。 比較の結果はブール値(True または False)です。
<式> == <式> # 右辺と左辺は同じ値
<式> != <式> # 右辺と左辺は異なる値
<式> > <式>
<式> >= <式>
<式> < <式>
<式> <= <式>
<式> in <式> # 左辺が右辺の要素にふくまれる。 (例: n in (0,1))
<式> not in <式> # 左辺は右辺の要素に含まれない。 (例: n not in (0,1))
<式> is <式> # 右辺と左辺は同じオブジェクト
<式> is not <式> # 右辺と左辺は異なるオブジェクト= =)と同一性(is)¶==(二つの等号)は両辺の式の値が等しいときにTrueとなります。
is は両辺の式が同じオブジェクトであるとき、Trueとなります。
a=[1,2,3]
b=[1,2,3]
print(a == b, a is b, id(a) == id(b))
True False False
id()は引数に与えられたオブジェクトの アイデンティティ(多くの場合は、オブジェクトのアドレス)を返します。
a, b はいずれも1,2,3を要素とするリストですが、別のオブジェクトです。
a=b=[1,2,3]
print(a == b, a is b, id(a) == id(b))
True True True
この場合、 a, b は同じオブジェクトです。もちろんその値も一致します。
a=[1,2,3]
b=(1,2,3)
print(a == b, a is b, id(a) == id(b))
False False False
リストとタプルは違う種類のオブジェクトなので、値としても異なります。
ここで質問です。
a=100 b=100とした時、
print( a == b, a is b, id(a) == id(b))はどんな結果になるでしょう? 結果を予想してから実行してみましょう。 解説は次回に。
a=100.0
b=100.0
print( a == b, a is b, id(a) == id(b))
True False False
Python では -5~256の整数は特別扱いされています。これらの整数はシステム初期化時に作成されたオブジェクトが使い回されます。
文字列やタプルなどのイミュータブルなオブジェクトでは、同様な最適化が行われる場合があります。
a="xyz"
b="xyz"
print(a==b, a is b, id(a)==id(b))
True True True
pythonでは expr1 < expr2 < expr3のような書き方が許されています。この式は、expr1 < expr2かつexpr2 < expr3の時に限ってTrueとなります。
この式は、(expr1 < expr2) and (expr2 < expr3)とは異なり、
expr2は一度だけ評価 されます。
x=1/2
0 < x < 1
True
and, or, not&, |, ^(exclusive or), ~ (invert)>> , <<論理演算はC言語の場合 ( &&, || , ! ) とは異なります。
print(
f"{(2.0 or 3.0) = :}, {(2.0 and 3.0) =: }, {(2.0 and 0 )= :}\n"
f"{(1 == 1) = :}, {(not 2.0) = :}, {(not 0.0) = :}\n"
f"{( (1.0 == 0.0) or 1.0 ) = :}\n"
f"{( (1.0 == 0.0) and 1.0 ) = :}\n"
)
(2.0 or 3.0) = 2.0, (2.0 and 3.0) = 3.0, (2.0 and 0 )= 0 (1 == 1) = True, (not 2.0) = False, (not 0.0) = True ( (1.0 == 0.0) or 1.0 ) = 1.0 ( (1.0 == 0.0) and 1.0 ) = False
再び、 ここで質問です。
((r:=1) or (r:=r+2)) and (r:=r+4)および
((r:=1) and (r:=r+2)) or (r:=r+4)の結果はそれぞれ何になりますか?
((r:=1) or (r:=r+2)) and (r:=r+4)
5
((r:=1) and (r:=r+2)) or (r:=r+4)
3
整数に対しては、 ビット毎の論理演算子: &, |, ^(exclusive or) , ~ (not)が使えます。 整数同士の論理演算の結果は、先ほど見たように、整数となります。
print(
f"{0x0f and 0xab = :02x}, {0x0f or 0xab = :02x},\n"
f"{0x0f and 0x00 = :02x}, {0x0f or 0x00 = :02x},\n"
f"{not 0xab = :02x}, {not 0x00 = :02x}"
)
0x0f and 0xab = ab, 0x0f or 0xab = 0f, 0x0f and 0x00 = 00, 0x0f or 0x00 = 0f, not 0xab = 00, not 0x00 = 01
同じデータにビットごと論理演算子を使った場合、結果は全く異なります。
print(
f"{0x0f & 0xab = :02x}, {0x0f | 0xab = :02x}, {0x0f ^ 0xab = :02x}\n"
f"{0x0f & 0x00 = :02x}, {0x0f | 0x00 = :02x}, {0x0f ^ 0x00 = :02x}\n"
f"{~ 0xab = :02x}, {~ 0x00 = :02x}\n"
f"{0xff & (~ 0xab )= :02x}, {0xff&(~ 0x00) = :02x}\n"
f"{0xff ^ 0xab = :02x}, {0xff ^ 0x00 = :02x}"
)
0x0f & 0xab = 0b, 0x0f | 0xab = af, 0x0f ^ 0xab = a4 0x0f & 0x00 = 00, 0x0f | 0x00 = 0f, 0x0f ^ 0x00 = 0f ~ 0xab = -ac, ~ 0x00 = -1 0xff & (~ 0xab )= 54, 0xff&(~ 0x00) = ff 0xff ^ 0xab = 54, 0xff ^ 0x00 = ff
Note:
(~n) + nをビット表現で考えると、 0xffffffff=-1になる。つまり (~n) == -n -1である。
制御などでビット反転が必要な時は、0xffffffffなどとのexclusive or(^)をとる方がいいでしょう。
f"{0xf0 & 0xff =:02x}, {0xf0 | 0x0f =:02x}, {0xf0 ^ 0xff =:02x}"
'0xf0 & 0xff =f0, 0xf0 | 0x0f =ff, 0xf0 ^ 0xff =0f'
前回定義したフィボナッチ関数と今回のフィボナッチ関数の実行速度を比べてみましょう。
まずは前回使った定義を再度示します。再帰的に定義されていることから、fibr()と名前を変えてあります。
def fibr(n:int)->int:
"""
returns the n-th fibonacci number.
"""
if n in (0,1):
return 1
return fibr(n-1) + fibr(n-2)
二つの関数の結果は一致しています。
[fib(i) for i in range(10)], [fibr(i) for i in range(10)],[fibl(i) for i in range(10)]
--------------------------------------------------------------------------- NameError Traceback (most recent call last) /var/folders/3h/lqzhtkt17vv47gbtv470wcp40000gn/T/ipykernel_70123/1399654788.py in <module> ----> 1 [fib(i) for i in range(10)], [fibr(i) for i in range(10)],[fibl(i) for i in range(10)] /var/folders/3h/lqzhtkt17vv47gbtv470wcp40000gn/T/ipykernel_70123/1399654788.py in <listcomp>(.0) ----> 1 [fib(i) for i in range(10)], [fibr(i) for i in range(10)],[fibl(i) for i in range(10)] NameError: name 'fib' is not defined
ここでは簡単のために、jupyterのセルマジック %%timeitを使って、プログラムの実行速度を測ってみます。
%%timeit
n=10
fibr(n)
%%timeit
n=10
fib(n)
セルマジック%%timeitに変わって、ラインマジック%timeitも使えます。
また、timeit モジュールを使って、直接に実行速度を計算することもできます。
n=10
%timeit fibr(n)
%timeit fib(n)
Nrep=1000000
import timeit
print(timeit.timeit("fib(n)",
setup="n=10",
globals=locals(),
number=Nrep)/Nrep)
%%timeit
n=10
fibl(n)
timeitモジュールを使って、より詳細にしらべることもできます。
import timeit
(n:=0, \
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibl(n)", globals=locals(), number=1),\
timeit.timeit("fibr(n)", globals=locals(), number=1)),\
(n:=10, \
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibl(n)", globals=locals(), number=1),\
timeit.timeit("fibr(n)", globals=locals(), number=1)),\
(n:=20, \
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibl(n)", globals=locals(), number=1),\
timeit.timeit("fibr(n)", globals=locals(), number=1)),\
(n:=30, \
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibl(n)", globals=locals(), number=1),\
timeit.timeit("fibr(n)", globals=locals(), number=1))
for n in range(0,40,10):
print(
n,
timeit.timeit("fib(n)", globals=globals(), number=1),
timeit.timeit("fibl(n)", globals=globals(), number=1),
timeit.timeit("fibr(n)", globals=globals(), number=1)
)
今日の講座では、以下の項目についてご説明しました。
python3の制御構造:while文
if文,while文, for文: 制御文/制御構造break/continue/pass/...(Ellipsis)代入式
実行時間の測定:timeitモジュール
ここでは、フィボナッチ関数を高速化してみます。 numbaのjitモジュールを使います。
@jitはpythonのデコレーターという機能で、定義された関数に前処理を付け加えることができます。ここでは前処理として、pythonの関数をnumba.jitでコンパイルして、
機械語バージョンの関数を使って関数を評価します。
import numba
from numba import jit
import random
@jit(nopython=True)
def fibn(n:int)->int:
if n in (0, 1):
return numba.longlong(1)
a=b=numba.longlong(1)
while (n := n-1 ) > 0:
a, b = b, a+b
if (b < 0):
raise ValueError("Negative result")
return b
fibn(0)
最後の行で、fibn()は機械語にコンパイルされ、以降はfibn()の評価にこの機械語プログラムが使われます。
print(
[fib(i) for i in range(10)],"\n",
[fibn(i) for i in range(10)],
)
結果は同じになっているようなので、実行速度を測ってみます。
%%timeitはjupyterのセルマジックの一つで、timeitモジュールをつかって、セルの実行時間を測定します。
%%timeit
n=40
fib(n)
%%timeit
n=40
fibn(n)
と大幅に改善されています。
しかし、別の極端な場合(n=0)をみると、jit版の方が時間がかかっています。 機械語のプログラムの呼び出し、戻り値のPythonへの変換などのオーバーヘッドがあるためと考えられます。
%%timeit
n=0
fib(n)
%%timeit
n=0
fibn(n)
これら二つの関数は, n=91までは同じ値を返します。
[(i,fib(i)) for i in range(90,92,1)], [(i,fibn(i)) for i in range(90,92,1)]
しかし、n=92の場合を計算してみると、
try:
print(f"{fib(92)=:}")
print(f"{fibn(92)=:}")
except ValueError as m:
print("Error!",m)
とfibnはエラーになってしまいます。これは、python3の整数に上限はありませんが、numbaでコンパイルされた関数のfibn中では、オーバーフローにより、正であるべき変数が負になったためです。
0x7fffffffffffffff > (4660046610375530309 + 7540113804746346429)
jitでコンパイルされる関数でuint64=ulonglongとして、エラーを回避できるか試してみましょう。
@jit(nopython=True)
def fibln(n:int)->int:
if n in (0, 1):
return numba.uint64(1)
a=b=numba.uint64(1)
for i in range(1,n):
a, b = b, a+b
if (b < 0):
raise ValueError
return b
fibln(0)
fibln(92),fib(92)
とn=92に対しては、正しいあたいがもとまりました。ところが、n=93については、
fibln(93),fib(93)
と異なった値が出てきます。これは結果を16進表示してわかるように、結果がuint64で表現できる最大の値をこえているためです。
f"{fib(93) =:018x}",f"{fibln(93) =:018x}",
いくら高速でもこれでは困ります。 整数を諦めて、 結果を浮動小数点で求めることもできます。
@jit(nopython=True)
def fibfn(n:int)->int:
if n in (0, 1):
return numba.uint64(1)
a=b=numba.float64(1)
for i in range(1,n):
a, b = b, a+b
if (b < 0):
raise ValueError
return b
fibfn(0)
[(i,fibfn(i)) for i in range(90,94,1)], [(i,fib(i)) for i in range(90,94,1)]
これでとりあえずは結果が真の値から大きくずれてしまうことはありません。(float64の精度範囲で一致) しかし、 n>1475ではfloat64の表現できる数値を超えてしまいます。
fib(1475),fibfn(1475), fib(1476), fibfn(1476)
import timeit
(n:=0, \
timeit.timeit("fib(n)", globals=globals(), number=1),\
timeit.timeit("fibn(n)", globals=globals(), number=1)),\
(n:=3,\
timeit.timeit("fib(n)", globals=globals(), number=1),\
timeit.timeit("fibn(n)", globals=globals(), number=1)),\
(n:=30,\
timeit.timeit("fib(n)", globals=globals(), number=1),\
timeit.timeit("fibn(n)", globals=globals(), number=1)),\
(n:=91,\
timeit.timeit("fib(n)", globals=globals(), number=1),\
timeit.timeit("fibn(n)", globals=globals(), number=1))
@jit(nopython=False)
def fibrn(n:int)->int:
if n == 0 or n == 1:
return numba.int64(1)
return fibrn(n-1) + fibrn(n-2)
fibrn(0),fibr(0)
(n:=0,
timeit.timeit("fibr(n)", globals=locals(), number=1),\
timeit.timeit("fibrn(n)", globals=locals(), number=1),\
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibn(n)", globals=locals(), number=1),\
timeit.timeit("fibl(n)", globals=locals(), number=1),\
timeit.timeit("fibln(n)", globals=locals(), number=1))
(n:=34,
timeit.timeit("fibr(n)", globals=locals(), number=1),\
timeit.timeit("fibrn(n)", globals=locals(), number=1),\
timeit.timeit("fib(n)", globals=locals(), number=1),\
timeit.timeit("fibn(n)", globals=locals(), number=1))
timeit.Timer("(fibrn(20))", globals=locals()).autorange(lambda number, time_taken:print(number, time_taken))
timeit.timeit("(fibrn(0))", globals=locals(), number=1),\
timeit.timeit("(fibrn(10))", globals=locals(), number=1),\
timeit.timeit("(fibrn(20))", globals=locals(), number=1),\
timeit.timeit("(fibrn(30))", globals=locals(), number=1),\
timeit.timeit("(fibrn(35))", globals=locals(), number=1),\
timeit.timeit("(fibrn(40))", globals=locals(), number=1),\
timeit.timeit("(fibrn(43))", globals=locals(), number=1)
timeit.timeit("(fibr(0))", globals=locals(), number=1),\
timeit.timeit("(fibr(10))", globals=locals(), number=1),\
timeit.timeit("(fibr(20))", globals=locals(), number=1),\
timeit.timeit("(fibr(30))", globals=locals(), number=1),\
timeit.timeit("(fibr(35))", globals=locals(), number=1)
%time fib(35)
%timeit fib(35)
%timeit fib(10)
%timeit fib(20)
@jit(nopython=False)
def foo(n:int)->int:
return numba.int64(n)
v=foo(0)
timeit.timeit("(foo(20))", globals=globals(), number=1)
プログラムの動作を理解する上で、関数実行プロファイルも役に立つ情報の一つです。
import cProfile
cProfile.run("fibr(30)")
@jit(nopython=True)
def Nfib(n:int)->int:
if n in (0, 1):
return numba.ulonglong(1)
a=b=numba.ulonglong(1)
while (n := n-1 ) > 0:
a, b = b, a+b+1
if (b < 0):
raise ValueError
return b
import math
Nfib(30)
cProfile.run("fibn(91)")
cProfile.run("fibrn(40)")
%load_ext cython
%%cythonセルマジックをつかうことで、 セルの中身をcythonでコンパイルします。
--annotateオプションは cythonの解析結果をみるのに使います。
%%cython --annotate
def fibc(n:int)->int:
cdef long a,b
"""
returns the n-th fibonacci number.
"""
if n in (0, 1):
return 1
a=b=1
for i in range(1,n):
a, b = a+b, a
if (a < 0):
raise ValueError("Negative result")
return a
[fibc(i) for i in range(8)],fibc(40)
実行速度を比較してみましょう。
%timeit fibc(40)
%timeit fibl(40)
%timeit fibn(40)
numbaに比べると、速度の低減率は低いですが、生のPythonに比べると、大幅に改善されていることがわかります。 cythonでもlong intのオーバーフローが発生する可能性があります。
print("(", end="")
print(fibl(93), end=", ")
try:
print(fibc(93), end=", ")
except ValueError as m:
print(m, end=", ")
try:
print(fibn(93), end=", ")
except ValueError as m:
print(m,end=", ")
print(")")
{kind=link}